验证码识别
很多网站服务会要求用户从一堆图片中选择特定物体,以此来验证用户是否真人。这种图片识别验证码(CAPTCHA)最常见的形式是在复杂的街景照片中识别自行车、斑马线、交通灯等日常物体。然而,最近有研究指出,一些本地运行的AI机器人使用特别训练的图像识别模型,已经做到100%的成功率,达到甚至超过了人类水平!

声明:本教程只能用于教学目的,如果用于非法目的与本人无关。
验证码杀手:YOLO模型
ETH苏黎世的博士生安德烈亚斯·普莱斯纳(Andreas Plesner)及其同事的最新研究聚焦于谷歌的reCAPTCHA v2,这一系统要求用户在图片网格中识别出包含诸如自行车、斑马线或交通灯等物体的街景图像。尽管谷歌几年前已经开始逐步淘汰该系统,转而采用“隐形”的reCAPTCHA v3以分析用户行为,但reCAPTCHA v2仍被全球数百万网站广泛使用,尤其在v3系统对用户的“人类”可信度打分过低时,常作为备用验证手段。
研究团队为了破解reCAPTCHA v2,使用了开源的YOLO(You Only Look Once)目标识别模型,这一模型因其实时检测物体的能力而备受青睐,甚至早在电子游戏作弊机器人中就得到了应用。研究者将这一模型进行了微调,使用了1.4万张标记过的交通图像进行训练,最后得到了一个能够对验证码网格图像进行精准识别的系统。
为了规避谷歌对机器人行为的检测,研究团队采取了多种措施,比如使用VPN来避免因IP地址重复尝试而被发现,同时还设计了一个特殊的鼠标移动模型,以模拟人类用户的活动。另外,自动化代理也利用了真实浏览器和浏览历史中的cookie信息,使其表现得更加“人性化”。
验证码全面沦陷
研究显示,根据不同的物体类别,YOLO模型对验证码的识别准确率从69%(摩托车)到100%(消防栓)不等。综合这些措施,机器人成功地一次次突破了验证码防线,有时候甚至比人类挑战的次数更少。尽管这种提升对比人类并无显著统计学意义,但也足以证明这项技术的有效性。
过去,学术界曾多次尝试利用图像识别模型来破解reCAPTCHA,但成功率大多在68%到71%之间浮动。而此次AI识别验证码的成功率首次达到100%,标志着我们正式进入了“后验证码时代”。
然而,这并不是验证码的首次“沦陷”。早在2008年,研究人员就展示了如何训练机器人突破专为视觉障碍用户设计的音频验证码;到了2017年,神经网络也已经能够破解那些要求用户输入乱码字体中字母的文本验证码。
如今,随着本地运行的AI也能轻松破解基于图像的验证码,人类身份识别的技术将继续转向更微妙的设备指纹识别方法。谷歌云的一位发言人向《新科学家》表示:“我们非常专注于帮助客户保护用户,同时尽量不显示视觉挑战,这也是为什么我们在2018年推出了reCAPTCHA v3。今天,reCAPTCHA在全球700万个网站上的大部分保护机制已经完全‘隐形化’。我们正在持续提升reCAPTCHA的能力。”
人与机器的识别边界正在模糊
随着人工智能系统在越来越多的任务上逐步逼近甚至超越人类能力,确保网络另一端的用户是一个真人变得越来越难。
正如论文作者所写:“从某种意义上说,一个好的验证码可以在最智能的机器与最不智能的人类之间划分精确界限。”而随着机器学习模型逐渐接近人类能力,找到一个“好”的验证码(技术)变得越来越困难。
验证码的历史与发展
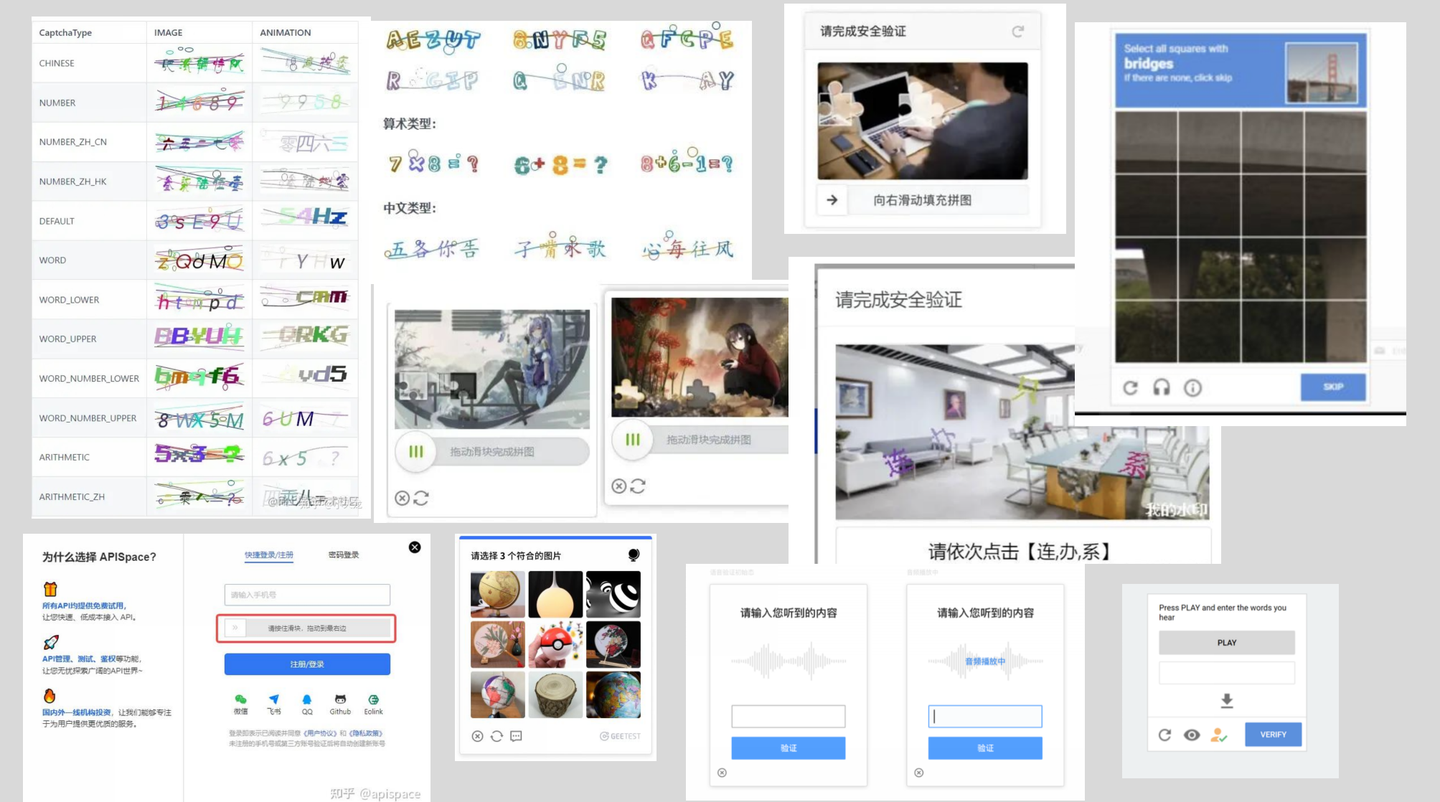
验证码,全称为“Completely Automated Public Turing test to tell Computers and Humans Apart”,即全自动区分计算机和人类的图灵测试,Captcha。早在上个世纪90年代,为了防止恶意的网络机器人行为,像邮件轰炸、暴力破解密码等,验证码应运而生。
最初的验证码是简单的文本字符,如用户只需输入一组扭曲的字母和数字。然后验证码发展到图像验证码,例如,要求用户识别哪些图片中包含某个特定对象(比如猫、狗或汽车等)。随着技术的发展,更为复杂的验证码类型出现了,例如逻辑验证码(例如,3+4=?),音频验证码(用户必须听音频然后输入听到的字符)和3D验证码(用户需要解读3D对象或者场景)。
此外,也有一些新的验证码设计,为了提高用户体验同时维护网站安全,它们需要用户进行更为人性化的操作。例如,滑动验证码让用户通过滑动解锁,点击验证码让用户点击特定的图片或文字,旋转验证码则要求用户调整图片到正确的方向。
一些大公司也开发了自己的验证码系统。例如,Google的reCAPTCHA v2引入了复杂的图像识别任务,需要用户选择包含特定物体(如汽车,交通灯)的图片;而Google的reCAPTCHA v3则摒弃了用户交互的方式,通过分析用户的行为模式来确定是人类还是机器。同样,第三方验证服务如GeeTest CAPTCHA和hCaptcha等,也为网站提供了验证服务,使得他们可以更好地防止自动化的恶意行为。
验证码破解的历史与发展
验证码破解的历史,与验证码的发展紧密相连。早期的验证码破解主要依赖于OCR(Optical Character Recognition,光学字符识别)技术,这是一种将图像中的文本转换为机器可读的字符的技术,用于识别简单的文本验证码。
然而,随着验证码的复杂性的增加,验证码破解也需要更为复杂的技术。例如,对于图像验证码,可能需要使用图像处理技术来处理噪声和扭曲。这可能包括灰度化(将图像转换为黑白),二值化(将图像进一步简化为只有黑和白两种颜色),边缘检测(识别图像中的边缘)等步骤。
对于更为复杂的验证码,例如点击验证码和旋转验证码,可能需要使用更复杂的机器视觉技术。这可能涉及到特征提取(识别图像中的重要特征),对象识别(识别特定的对象或形状),甚至深度学习(训练模型来识别复杂的模式)。
近年来,随着人工智能的发展,机器学习和深度学习等技术也被应用于验证码破解中。例如,卷积神经网络(CNN)已经被用来识别复杂的图像验证码,而递归神经网络(RNN)可以用于识别音频验证码。这些模型通过在大量的数据上进行训练,可以学习到识别验证码的复杂模式,大大提高了验证码破解的准确性和效率。
新时代高精准识别验证码的人工服务
人工验证码识别服务是一种基于人工智能或人工劳动力的验证码识别解决方案。当机器无法识别复杂的验证码时,这种服务能够提供相对高效且准确的解决方案。

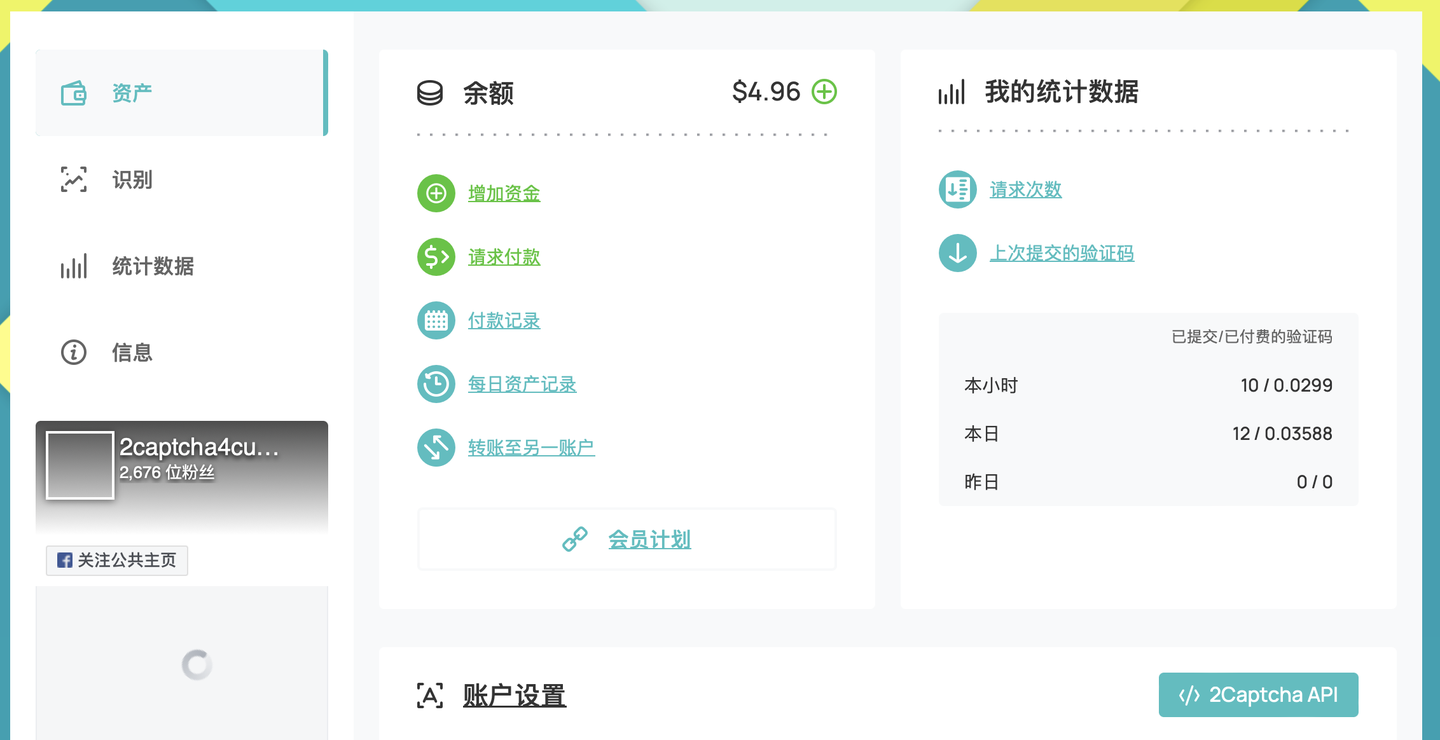
2Captcha
2Captcha是一种基于人工劳动力的验证码识别服务。它提供了一个API接口,允许开发者将无法识别的验证码发送到2Captcha服务。然后2Captcha的工人会手动识别并返回结果。这种服务对处理图像验证码、文本验证码、点击类验证码、GeeTest、reCAPTCHA、FunCaptcha等复杂验证码有很高的准确率,并且提供多种编程语言的接口文档Python、PHP、Java、Go、Ruby、C++、C#。2Captcha的主要优点是其优异的精确性和灵活的API,使得开发者可以轻松集成并在不同环境中使用。
云码
云码基于图像识别技术和人工辅助提供验证码识别服务,提供在线普通图片、滑动、点选、谷歌、HCaptcha、数字计算题验证码识别服务。其对于图像类的验证码有比较好的效果,尤其是各种不同类型的图像验证码。但其对于复杂的验证码存在准确率下降和识别时间较长的情况、验证码种类跟进相较也会慢一些。
冰拓
冰拓可识别各种常见图片验证码,AI识别 + 真人识别双模式,可高效识别坐标题、计算题、字符题、滑块题、拼图题等各种图片。API支持Python、JAVA、PHP、JAVASCRIPT调用,支持按键精灵集成。对于多样化的滑块、拼图、旋转、坐标有自己独特的处理方法和提供定制服务,不支持谷歌验证码。
超级鹰
超级鹰是专业的人工打码平台,对图片数据进行精准、快速分类处理,并实时返还分类结果。支持英文数字、中文汉字、坐标选择计算等多种类型图片验证码,并且提供定制化的验证码识别服务。对于通用的验证码、传统验证码有较好的识别效果,但对于复杂验证码尚未提供更多服务。
验证码破解实战
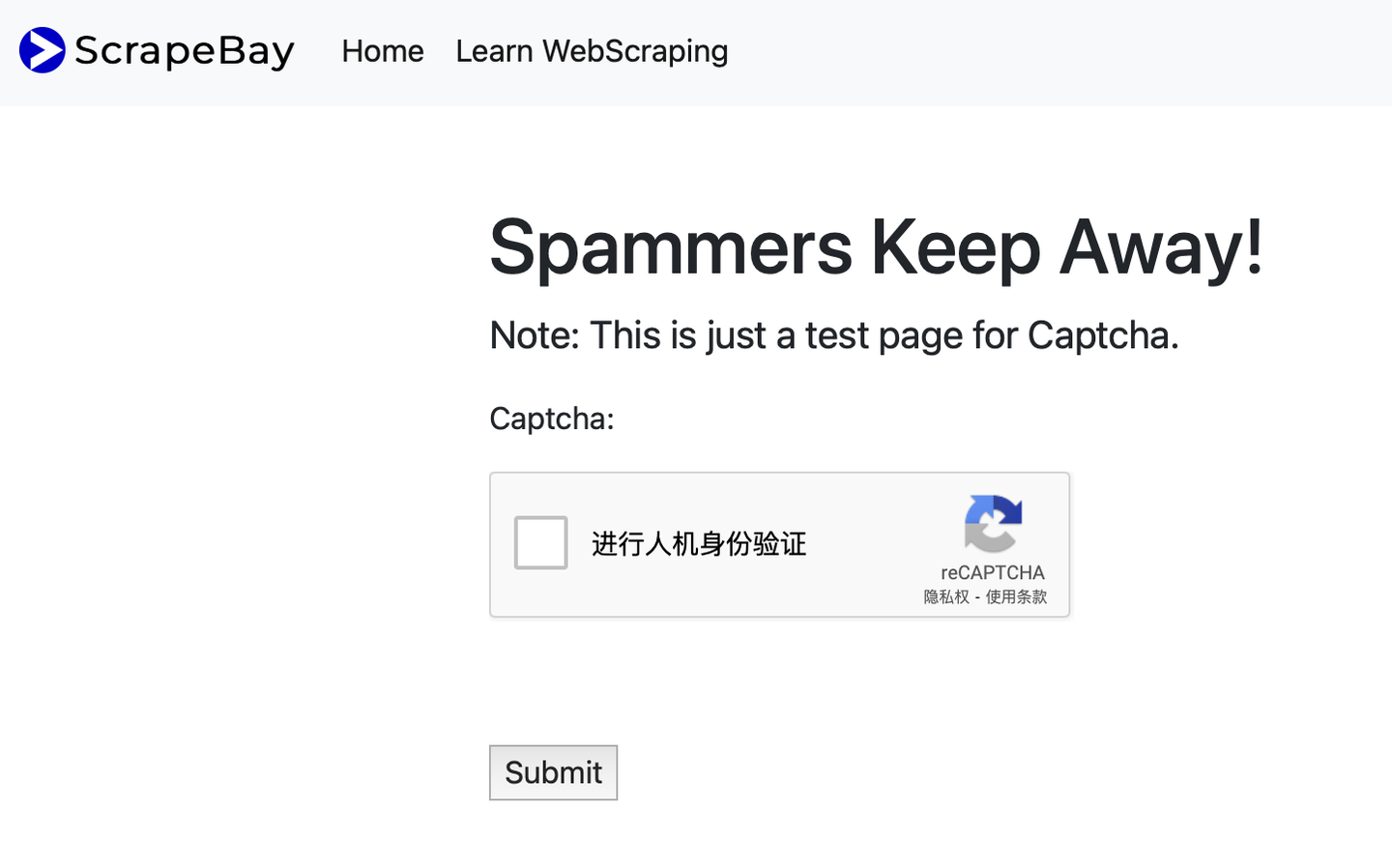
以2Captcha破解reCAPTCHA v2为例
- 注册2Captcha,https://cn.2captcha.com/ ,
- 目标破/-解https://www.scrapebay.com/spam 网站reCAPTCHA v2
- 拿到2Captcha API_KEY

- 拿到google sitekey
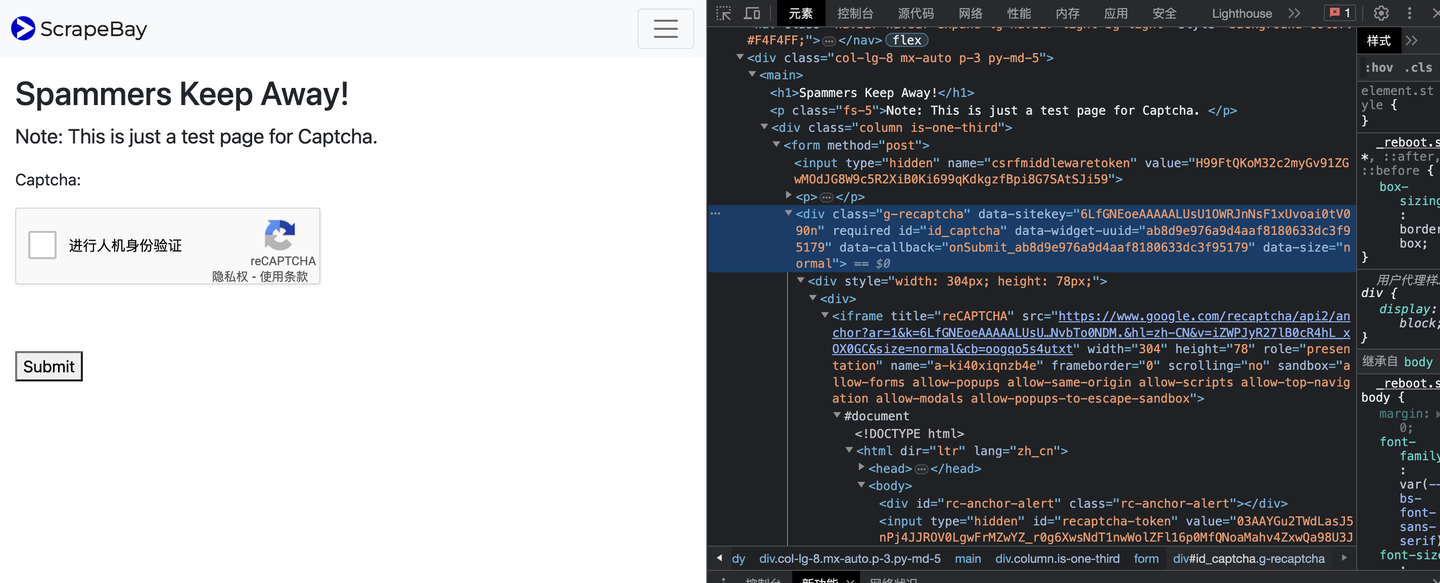
- 破解验证码
安装2captcha-python
1 | pip3 install 2captcha-python |
破解验证码
1 | # 导入BeautifulSoup、TwoCaptcha、requests库 |
运行结果:

- 获得验证码后的页面数据
包含破解验证码的全部代码如下:
1 | # 导入BeautifulSoup、TwoCaptcha、requests库 |
网站验证后的页面: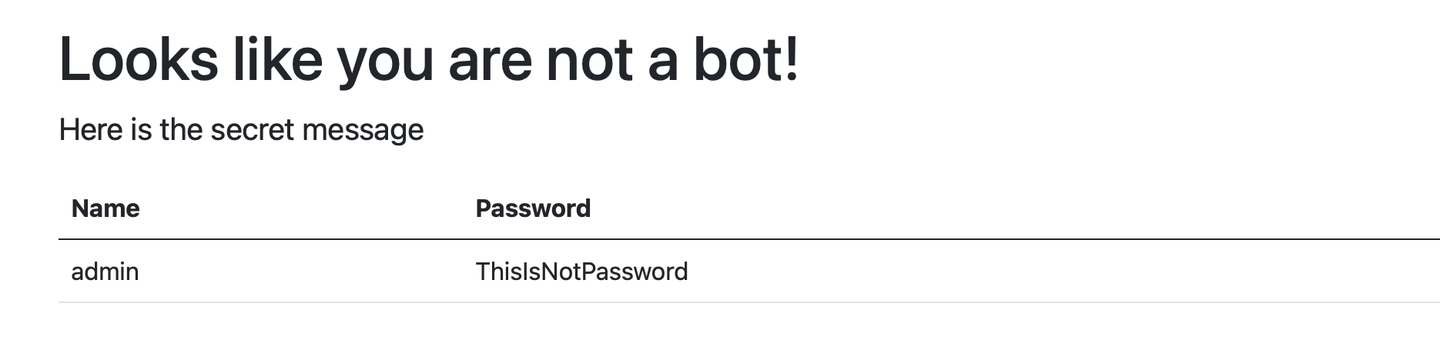
运行结果:

至此我们使用2Captcha服务破解了reCAPTCHA v2,并获得了需要爬取的内容。2Captcha服务包含多种验证码格式,均可以使用上述的流程,修改其中不同验证码的细节部分,攻克验证码的识别难点。
在图中顺序点击文字
该问题本质是图片的detection问题,是图像处理中的经典问题。使用R-cnn,Yolo,SSD等深度学习技术完全可以解决。针对这个验证码,我考虑了两种方法:
直接使用R-cnn,Yolo,SSD这样的模型进行端到端训练
使用R-cnn,Yolo,SSD先进性检测,后进行识别
最终选择了方法2,原因是:
端到端训练难度大
需要大量训练样本
最终选择Yolo作为定位网络,网络框架使用 Darknet: Open Source Neural Networks in C
训练过程
定位训练
网络准备cfg/yolo-origin.cfg
爬取验证码图片,最初爬取500张,进行极为痛苦的手工标注。因为打算只定位汉字一类,故只需要标框就可以了,darknet有提供Yolo训练代码。
在这里需要注意修改cfg/yolo-origin.cfg中 filter=30,classes=1。num=5代表每个框最多可以预测多少类,这里我没有进行修改 。
1 | [convolutional] |
filter计算公式如下:
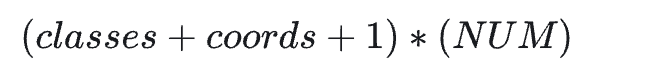
因为检测只有汉字1类,坐标为中心点坐标+图片宽高,共4个数,还有1个置信度,每个cell预测5个box,故最后输出
可以提供通过url进行识别破解的demo(针对网易点选验证码)
训练配置cfg/yolo-origin.data
训练配置文件格式如下
1 | backup = products/backup |
backup 用于保存训练权重
classes代表定位有几个类
names代表网络前向时图片对应标签的名字,如下图中的dog bicycle truck。定位只需一类就写一个。
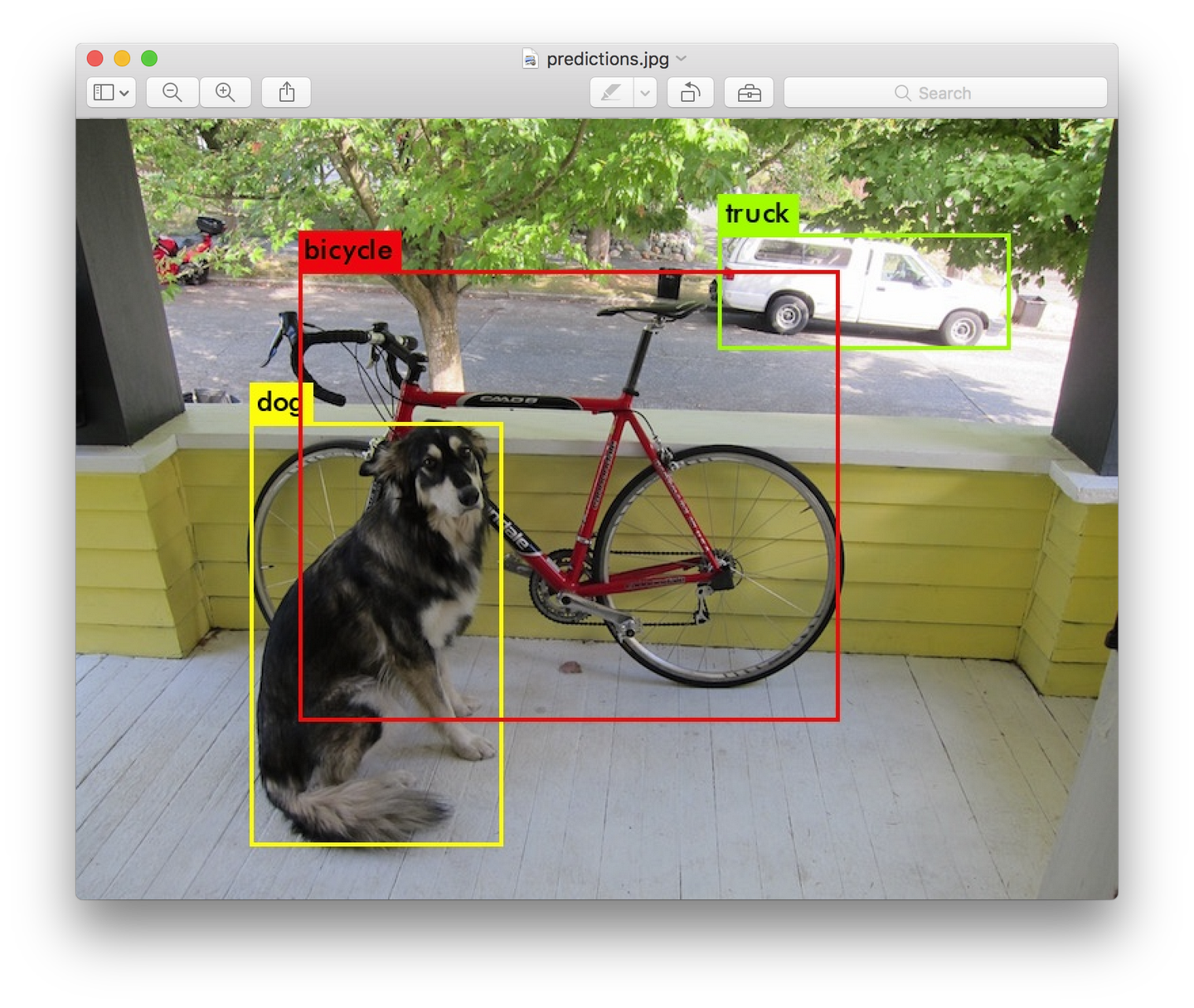
results 代表使用darknet valid选项时存放结果的位置。
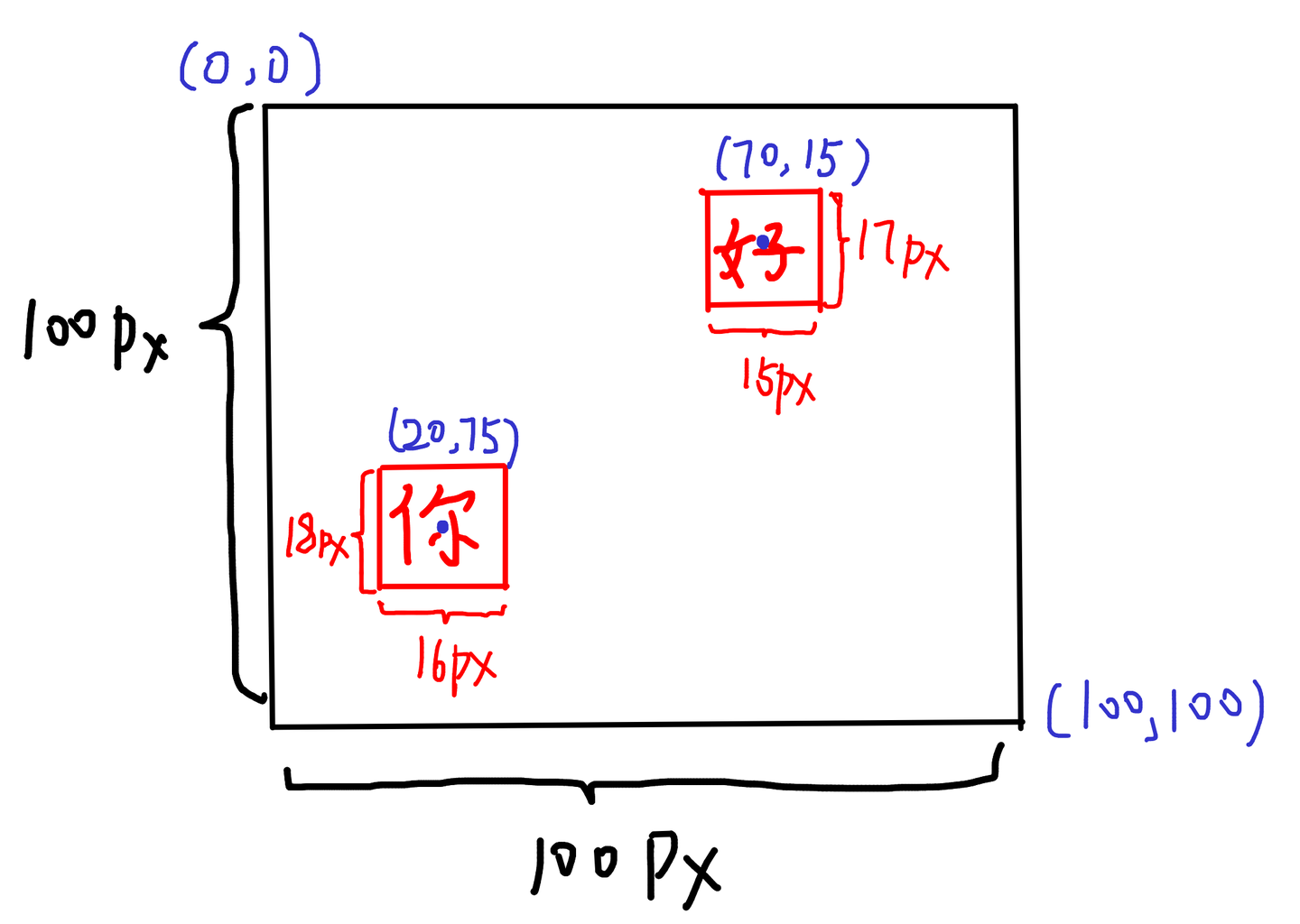
train & valid 代表存放训练 & 验证标签位置的路径,标签文件名需要与图片文件名一样,标签格式为 。其中object-calss代表类标签,因为只有一类所以为0;x & y代表中心点的相对坐标,width & height代表文字相对高度。
如下图为实例,你的标签为0 0.2 0.75 0.16 0.18 ,好的标签为 0 0.7 0.15 0.15 0.17 。所以整张图的标签为
1 | 0 0.2 0.75 0.16 0.18 |
trainval.txt 的内容为图片的路径,label与图片放在同一文件夹下并且文件名相同。
1 | products/trainval/0000172_6_0.jpg |
products/trainval文件夹内容
训练
1 | sh run.sh yolo_train |
识别训练
网络准备cfg/chinese-character.cfg
标准的全卷积识别网络。filter代表最后汉字数量。
1 | [convolutional] |
训练配置cfg/chinese.data
描述如下,名称相同的与检测描述一致。
1 | classes=3549 |
labels代表label的位置,names文件中存放所有编码后的label。如data/chinese_label.names
1 | abcdefg |
由于darknet中train存储训练图片的路径,图片的label包含在图片的绝对路径中如图片路径为/data/some_path/abcdefg.jpg,因为chinese_label.names中存在abcdefg编码,所以这张图片的标签为abcdefg。
注意
darknet在解析label时图片的绝对路径中如果包含多个label.names中的编码则会加载多个标签,导致无法训练,如:
label_names中如果包含1,2作为标签则 /data2/some_path/1.jpg这张图会解析到1 2均为这张图片的标签(data后的2以及1.jpg的1)。可以将标签加前导零或者使用全排列。
top 代表在valid的时候我们选取多少计算正确率,如top100代表分类出的概率前100为中存在正确的汉字即为正确;top1代表仅一个字对才算对。因为点选验证码会告诉你点击哪个字,所以识别结果的字有候选方案
训练
1 | sh run.sh chlassifier_train |
先使用yolo进行定位,定位后将图片进行切分,送入分类器进行分类。选取出现在候选字中的字符,返回位置即可。
Bug process_img_to_darknet_input 函数当子函数调用传入darknet中数据前8位发生错误
因为darknet教程使用的本地读取图片的方式,python接口使用的ctypes,我写的server通过网络加载图片,故需要将图片转换为darknet输入格式。
推测原因:可能由于c与python分配对象方式不同 process_img_to_darknet_input存在调用时, python在子函数进入栈分配堆内存与c分配方式不同。
Bug 内存泄露
修改darknet分配bbox函数,增加free函数,python每次申请后进行释放即可。
效果


https://github.com/cos120/captcha\_crack
https://cos120.github.io/crack/
一种点选验证码为例来讲解打码平台的使用方法,验证码的链接为: https://captcha3.scrape.center/
这个网站在每次登录的时候都会弹出一个验证码,用户名和密码均为 admin,其验证码效果图如下所示。
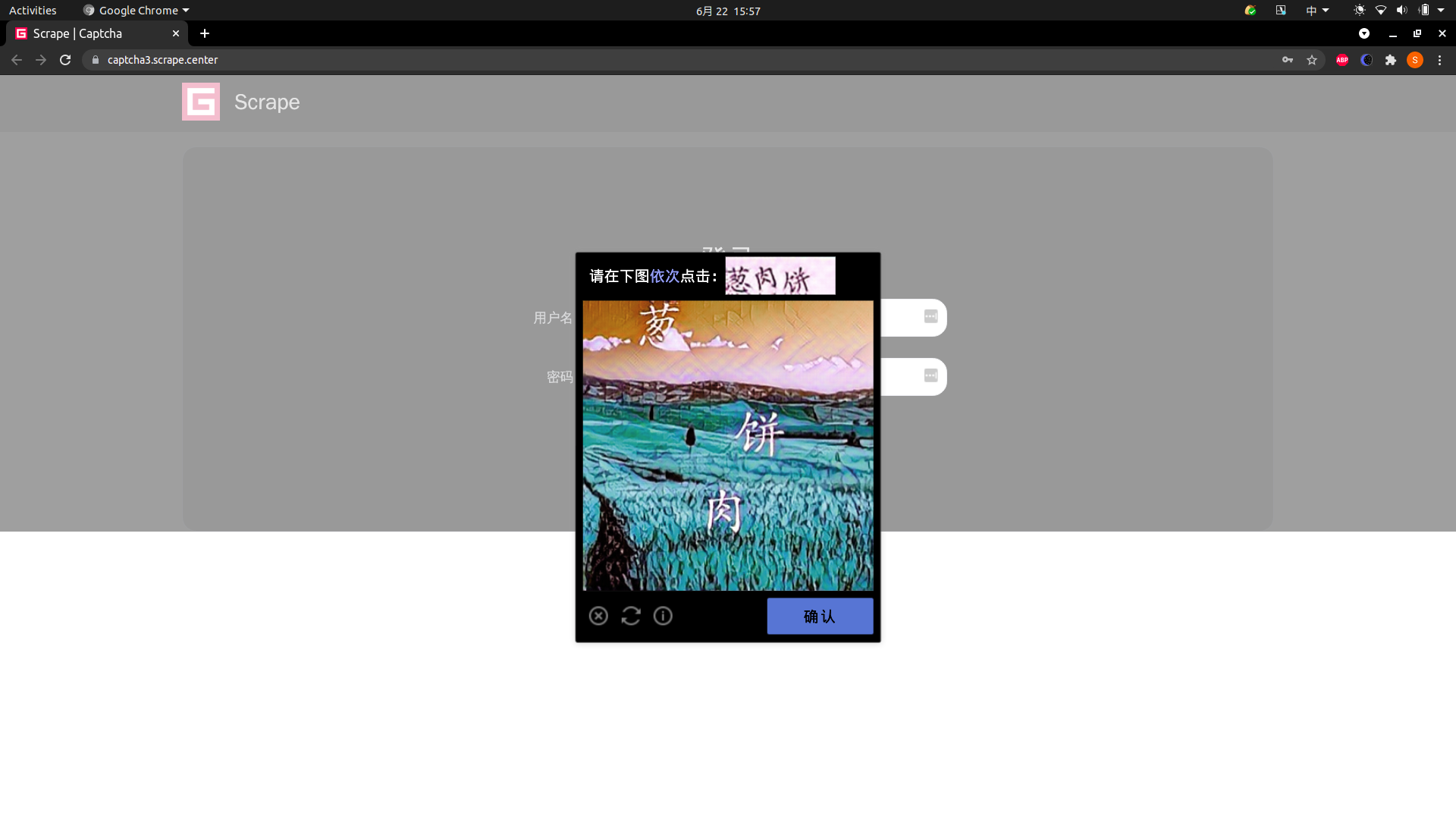
这个验证码上面显示了几个汉字,同时在图中也显示了几个汉字,我们需要按照顺序依次点击汉字在图中的位置,点击完成之后确认提交,即可完成验证。
这种验证码如果没有任何图像识别算法基础的话,是很难去识别的,所以这里我们可以借助打码平台来帮助我们识别汉字的位置。
准备工作
我们使用的 Python 库是 Selenium,使用的浏览器为 Chrome。
在本课时开始之前请确保已经正确安装好 Selenium库、Chrome 浏览器,并配置好 ChromeDriver,相关流程可以参考 Selenium 课时的介绍。
本课时使用的打码平台是超级鹰
,在使用之前请你自己注册账号并获取一些题分供测试,另外还可以了解平台可识别的验证码的类别。
打码平台
打码平台能提供的服务种类一般都非常广泛,可识别的验证码类型也非常多,其中就包括点触验证码。
超级鹰平台同样支持简单的图形验证码识别。超级鹰平台提供了如下一些服务。
- 英文数字:提供最多 20 位英文数字的混合识别
- 中文汉字:提供最多 7 个汉字的识别
- 纯英文:提供最多 12 位的英文识别
- 纯数字:提供最多 11 位的数字识别
- 任意特殊字符:提供不定长汉字英文数字、拼音首字母、计算题、成语混合、集装箱号等字符的识别
- 坐标选择识别:如复杂计算题、选择题四选一、问答题、点击相同的字、物品、动物等返回多个坐标的识别
具体如有变动以官网为准:https://www.chaojiying.com/price.html 。
这里需要处理的就是坐标多选识别的情况。我们先将验证码图片提交给平台,平台会返回识别结果在图片中的坐标位置,然后我们再解析坐标模拟点击。
下面我们就用程序来实现。
获取 API
在官方网站下载对应的 Python API,链接为:https://www.chaojiying.com/api-14.html 。API 是 Python
2 版本的,是用 requests库来实现的。我们可以简单更改几个地方,即可将其修改为 Python 3 版本。
修改之后的 API 如下所示:
1 | # -*- coding: utf-8 -*- |
验证码

结果:
1 | { |
这里定义了一个 Chaojiying类,其构造函数接收三个参数,分别是超级鹰的用户名、密码以及软件 ID,保存以备使用。
最重要的一个方法叫作 post_pic,它需要传入图片对象和验证码类型的代号。该方法会将图片对象和相关信息发给超级鹰的后台进行识别,然后将识别成功的 JSON返回。
另一个方法叫作 report_error,它是发生错误时的回调。如果验证码识别错误,调用此方法会返回相应的题分。
接下来,我们以 https://captcha3.scrape.center/ 为例来演示下识别的过程。
初始化
首先我们引入一些必要的包,然后初始化一些变量,如 WebDriver、Chaojiying对象等,代码实现如下所示:
1 | # -*- coding: utf-8 -*- |
这里的 USERNAME、PASSWORD是示例网站的用户名和密码,都设置为 admin即可。
另外 CHAOJIYING_USERNAME、CHAOJIYING_PASSWORD就是超级鹰打码平台的用户名和密码,可以自行设置成自己的。
另外这里定义了一个 CrackCaptcha类,初始化了浏览器对象和打码平台的操作对象。
接下来我们用 Selenium模拟呼出验证码开始验证就好了。
获取验证码
接下来的步骤就是完善相关表单,模拟点击呼出验证码了,代码实现如下所示:
1 | def open(self): |
这里我们调用了 open方法负责填写表单,get_captcha_button方法获取验证码按钮,之后触发点击,这时候就可以看到页面已经把验证码呈现出来了。
有了验证码的图片,我们下一步要做的就是把验证码的具体内容获取下来,然后发送给打码平台识别。
那怎么获取验证码的图片呢?我们可以先获取验证码图片的位置和大小,从网页截图里截取相应的验证码图片即可,代码实现如下所示:
1 | def get_captcha_element(self): |
这里 get_captcha_image方法即为从网页截图中截取对应的验证码图片,其中验证码图片的相对位置坐标由 get_captcha_position
方法返回得到。所以就是利用了先截图再裁切的方法获取了验证码。
注意:如果你的屏幕是高清屏如 Mac 的 Retina 屏幕的话,可能需要适当调整下屏幕分辨率或者对获取到的验证码位置做一些倍数偏移计算。
输出
1 | 成功获取验证码节点 |
最后我们得到的验证码是 Image对象。
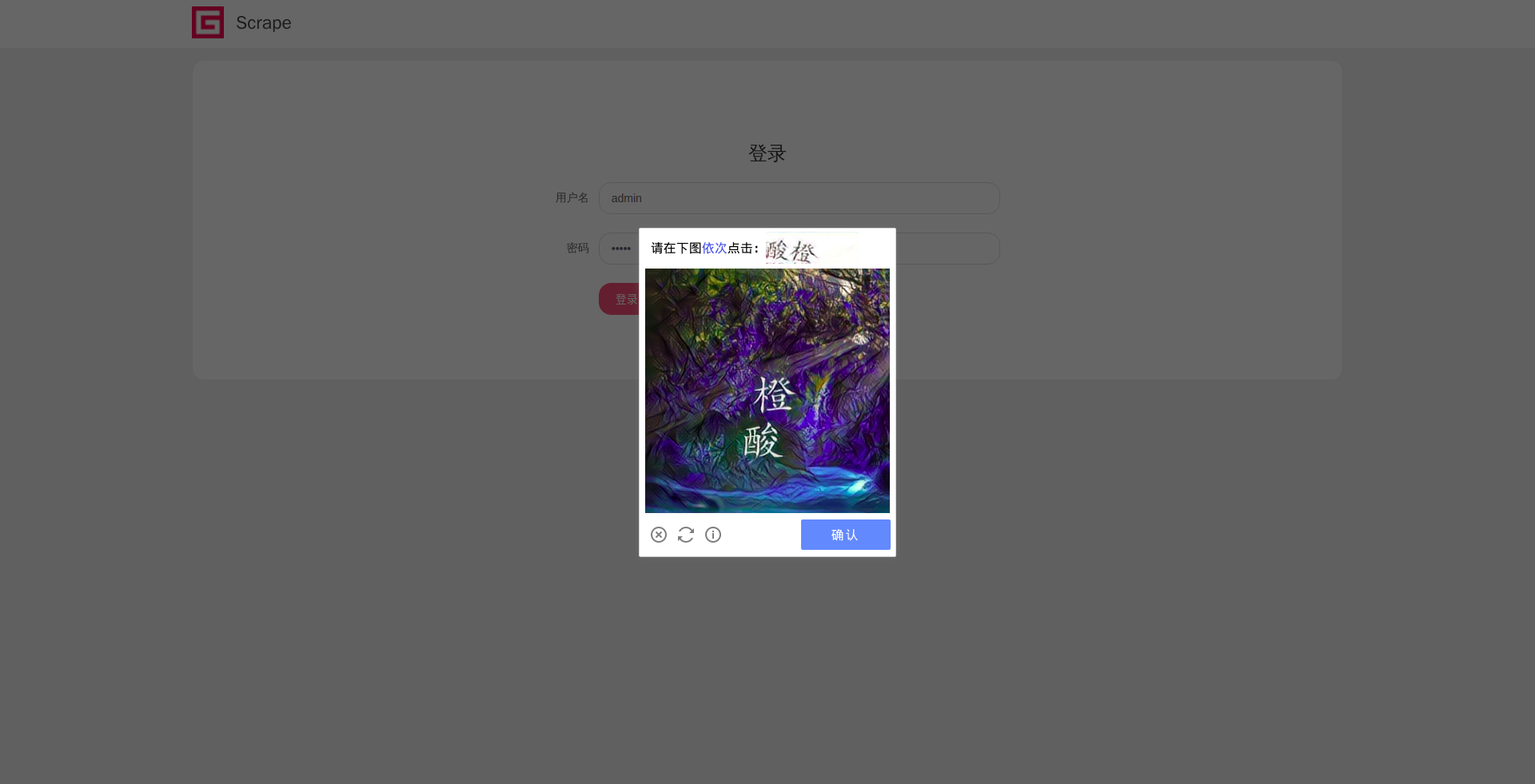
其结果样例如图所示。

识别验证码
现在我们有了验证码图了,下一步就是把图发送给打码平台了。
我们调用 Chaojiying对象的 post_pic方法,即可把图片发送给超级鹰后台,这里发送的图像是字节流格式,代码实现如下所示:
1 | def get_captcha(self): |
运行之后,result变量就是超级鹰后台的识别结果。可能运行需要等待几秒,它会返回一个 JSON 格式的字符串。
如果识别成功,典型的返回结果如下所示:
1 | { |
其中,pic_st就是识别的文字的坐标,是以字符串形式返回的,每个坐标都以 | 分隔。接下来我们只需要将其解析,然后模拟点击,代码实现如下所示:
1 | def get_points(self, captcha_result): |
这里用 get_points方法将识别结果变成列表的形式。touch_click_words方法则通过调用 move_to_element_with_offset方法依次传入解析后的坐标,点击即可。
这样我们就模拟完成坐标的点选了,运行效果如下所示。
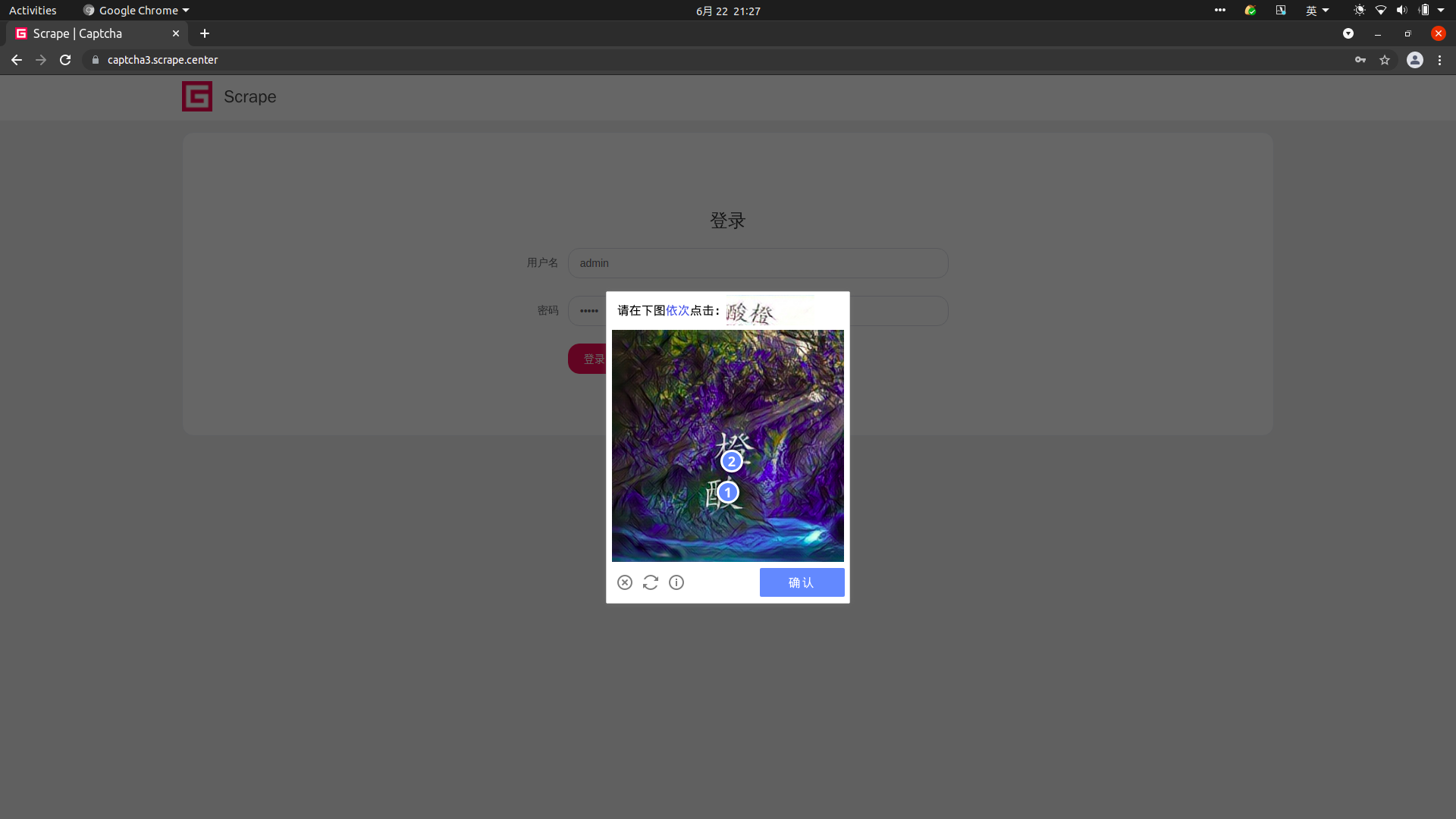
最后再模拟点击提交验证的按钮,等待验证通过就会自动登录,后续实现在此不再赘述。
如何判断登录是否成功呢?同样可以使用 Selenium的判定条件,比如判断页面里面出现了某个文字就代表登录成功了,代码如下:
1 | # 判定是否成功 |
比如这里我们判定了点击确认按钮,页面会不会跳转到提示成功的页面,成功的页面包含一个 h2 节点,包含“登录成功”四个字,就代表登录成功。
这样我们就借助在线验证码平台完成了点触验证码的识别。此方法是一种通用方法,我们也可以用此方法来识别图文、数字、算术等各种各样的验证码。
需要注意的有,注意验证码的类型,同时系统的识别率不是百分百,会有点选错误的情况,对于这种情况,可以重新呼出验证码或者提交给后台处理。
通过在线打码平台辅助完成了验证码的识别。这种识别方法非常强大,几乎任意的验证码都可以识别。如果遇到难题,借助打码平台无疑是一个极佳的选择。
常见20种验证码识别思路
1.滑块验证码
方案1:ddddocr https://github.com/sml2h3/ddddocr
方案2:opencv(canny做边缘检测,在做模板匹配)
方案3:yolov8 (m l模型) https://github.com/ultralytics/ultralytics
1.某验的滑块验证码 简单
2.某美的滑块验证码 简单
有混淆的图标,但是大小不一,目标检测,大小差不多的就是目标图标

3.某盾的滑块验证码 简单
简单,直接目标识别,或者图像匹配
4.某象的滑块验证码 简单
有混淆图标,但是匹配图标的验证更深,作为特征匹配,yolo可以实现

2.文字点选验证码
方案:
yolo目标识别+分类网络(resnet50 101)+根据提供的文字顺序点击
1.某验的文字点选验证码 简单


2.某盾的语序点选验证码 适中
文字角度,颜色,抖动(特征明显)
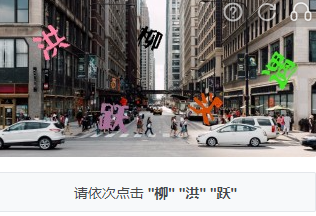
3.某美的文字点选 适中
字体只有角度旋转,颜色鲜艳,特征明显,可以生成样本自己训练
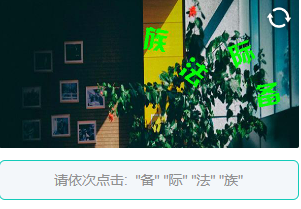
4.某象文字点选验证码 适中
文字比较有个性,颜色不一,有重影,需要的样本数量会比较多
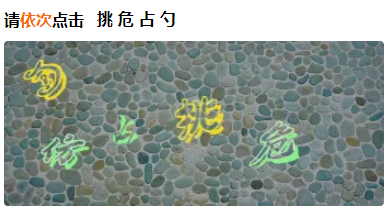
3.图标点选验证码
方案:
yolo目标识别+分类网络+根据提供的图标顺序点击(基本都是矢量图,特征明显)
1.某验的图标点选验证码 简单
图标识别

2.某盾的图标点选验证码 简单
图标是矢量图,三个定选项,2个多余的,有旋转,有白色的容易混淆
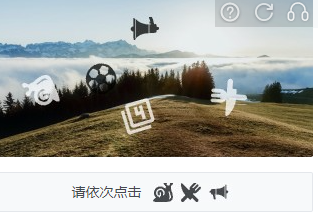
3.某美的图标点选 适中
颜色鲜艳,图标数量对应,特征明显

4.某象图标点选验证码 适中
矢量图是白色,没有旋转,拉伸,特征明显

4.语序点选验证码
方案:
目标识别+分类网络+固定句子(需要自己收集固定句子,做匹配)
1.某验的语序点选验证码 难
语序点选,句子不固定,句子样本量会比较大

2.某盾的语序点选验证码 适中
文字角度,颜色,抖动(都是四字成语)
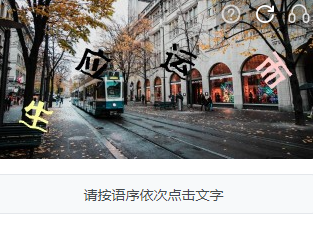
3.某美的语序点选验证码 适中
字体颜色鲜艳,只有角度,特征明显,四字成语

4.某象的语序点选验证码 适中
字体颜色明显,有重影和角度,需要大量样本,都是四字成语

5.空间推理验证码
方案:
一个物体多属性的问题,首先yolo找到目标,根据区域大小,确定图像的大小属性和位置;然后需要把形状,朝向,颜色做分类网络的one-hot编码,得出物体的属性后;接着padddleocr识别提示词;最后在根据语义词性分割得到具体要做什么。
1.某验的空间推理验证码 难

2.某盾空间推理 难
有朝向,颜色,大小写,字母,数字,立方体
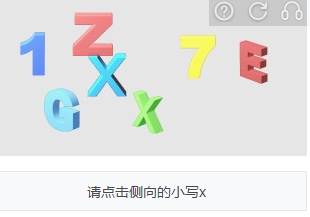
3.某美的空间推理验证码 适中
没有重叠,颜色鲜艳,大小不一,特征明显,问题简单,逻辑推理简单

4.某象的空间语义验证码 难
有二维图形,三维图形,大小写字母,语义简单(需要逻辑推理)

6.图像旋转
1.某象的旋转验证码 适中
方案:
需要把旋转圆的外圈干扰绿色去掉,放大到原来的大小,旋转角度通过计算重合边缘的Sobel梯度来寻找最佳旋转角度

7.词序选词
方案:
有颜色,两个字组合,固定组合(需要数据量大),固定的四字语序。yolo目标检测,resnet50或者resnet101分类
1.某盾语序选词 难

8.消消乐
1.某验的消消乐验证码 适中
方案1:前提图像切割位置精确(每个图像分割出来都是一样的大小,位置相同),直接用md5计算图像的值来区分图像的类别。
方案2:怕图像切割位置不精确,直接用resnet18分类网络区分图像的类别。

9.五子棋
1.某验的五子棋验证码 适中
棋盘的位置固定,区分各个棋子的颜色,判断四个棋子在一条线上,把另外的一个补上
方案1:前提图像切割位置精确(每个图像分割出来都是一样的大小,位置相同),直接用md5计算图像的值来区分颜色。
方案2:怕图像切割位置不精确,直接用resnet18分类网络区分颜色。

10.九宫格
方案:
对每个图片进行图像分类,然后选择同一类的3个图。需要大量样本,直接就是分类resnet101网络
1.某验的九宫格验证码 高

2.yescaptcha 难
方案:
yolo (m,l,x)的目标检测可以检测8个类别中的6个,在单独训练剩下的人行道和楼梯基本就能完成任务
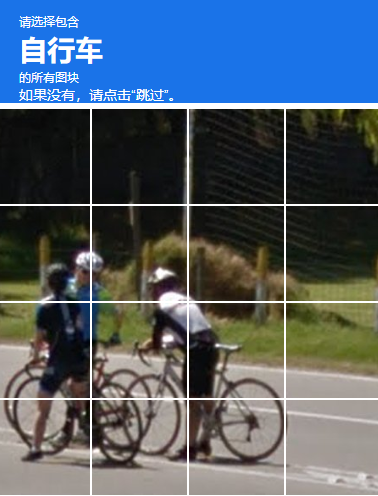
自行车(ok),摩托车(ok),公交车(ok),人行道,小轿车(ok),消防栓(ok),红绿灯(ok),楼梯(8个类别)
去除噪点,识别特定几个的物体,点击完了,在提交

先拼接,识别要求的物体图像所在区域
10.推理拼图
1.某盾的推理拼图验证码 适中
方案:
图片只有四张,用图像分类resnet50或者resnet18,总计8个分类,用位置作为分类。让模型记住图像位置。这样一旦有图像位置对不上,就能直接识别出来。
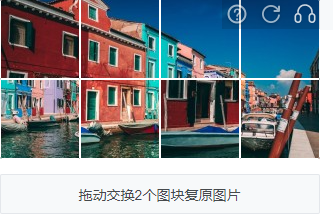
2.某象的乱序拼图验证码 适中
方案1:遗传算法
方案2:计算图像边缘的直方图或者sobel算子

3.某象的滑动还原验证码 适中
方案:
计算图像边缘的直方图或者sobel算子

11.障碍躲避
1.某盾的障碍躲避验证码 适中
方案:
小球固定的,yolo识别图标的位置,resnet50分类图标,把小球和目标连起来,路径必须绕过识别的图标位置

12.面积验证
1.某象的面积验证码 适中
方案:
用opencv找到线这个边界:先灰度,后二值化,放大这个线连成线,接着计算面积,最后得出结果

13.差异点击验证
1.某象的差异点击验证码 适中
方案:
yolo定位目标,用resnet50网络 计算图像之间的余弦相似度

14.语音验证
方案:
阿里的SenseVoice 1s内识别完内容
1.某象的语音验证码 适中
播放四个数字,随便一个语音识别就可以
2.售票网 适中
有噪音,需要去噪音在识别
15.字体识别
1.某象的字体识别验证码 适中
方案:
不同风格的字体都跟其他7个不一样,要么空心,要么细,要么粗。用图像分类算法,总计:粗,细,空心三个分类

16.刮刮卡
1.某象的刮刮卡验证码 难
在中间画一笔,这一笔中肯定能刮开目标的一部分,在用yolo制作一个目标检测模型,确定这个点。在点周围画一个圆。

17.轨迹图
vaptcha的轨迹验证码 难
方案1:yolo关键点检测,再把关键点连接起来
方案2:maskrcnn或者pspnet网络做图像分割,在用skimage里现成的函数提取骨架。



18.数字字母识别
1.不定长的数字字母识别
cnn和lstm网络都可以
19.计算题
方案1:rcnn做训练,
方案2:yolo做目标检测,分类检测图标,转换为数学作加减
1.数字计算

2.汉字计算

浏览器驱动下载:
http://chromedriver.storage.googleapis.com/index.html
https://googlechromelabs.github.io/chrome-for-testing/\#stable
自动检测识别模型:
UltralyticsYOLO11YOLO11:https://docs.ultralytics.com/zh
用用验证码离线本地识别SDK:
https://github.com/sml2h3/ddddocr
hackhttp框架重放数据包:
https://github.com/BugScanTeam/hackhttp
web弱口令自动检测:
https://github.com/TideSec/web\_pwd\_common\_crack
后台测试目标:
https://ppm.webank.com:13284/login
http://154.83.15.10:82/user/authentication/login?goto=/
https://auth.alipay.com/login/index.htm
自动登录工具:
https://github.com/browser-use/browser-use
https://github.com/linxinloningg/Boom
https://github.com/Fly-Playgroud/Boom
https://github.com/yzddmr6/WebCrack
云码平台:
https://www.jfbym.com/price.html
代理工具:
https://github.com/snail007/goproxy
https://github.com/jhao104/proxy\_pool
https://github.com/3proxy/3proxy
爬虫工具:
https://github.com/AbnerEarl/scan
https://github.com/chaitin/rad
敏感信息检测工具:
https://github.com/gitleaks/gitleaks
https://github.com/trufflesecurity/trufflehog
DNS攻击工具:
https://github.com/AbelChe/cola\_dnslog
微信解析工具:
https://github.com/xaoyaoo/PyWxDump/blob/master/doc/UserGuide.md
数据库转换工具: