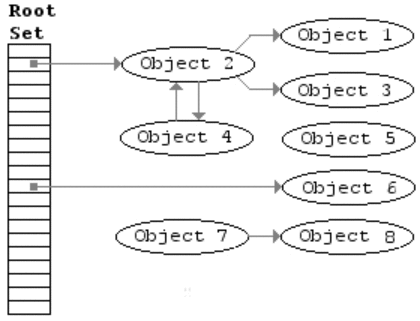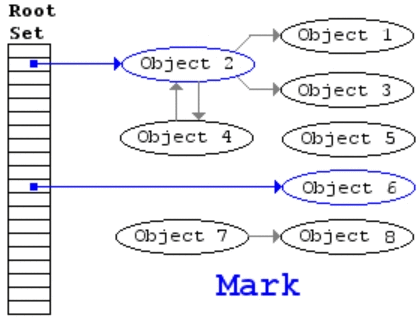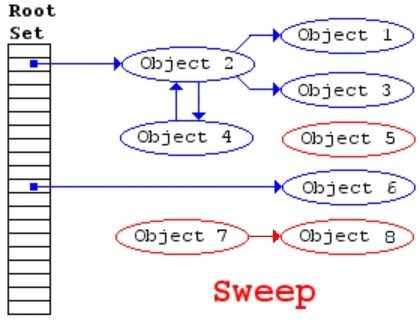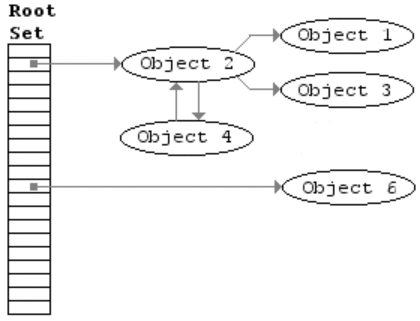
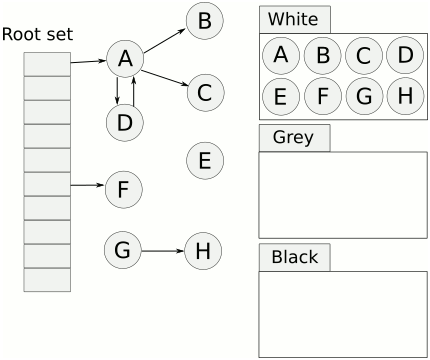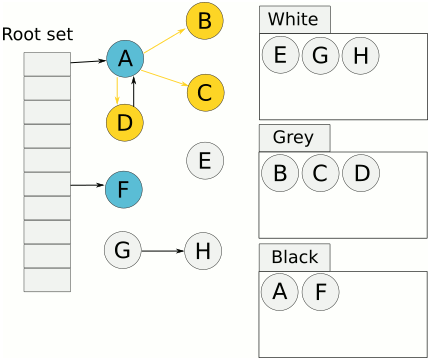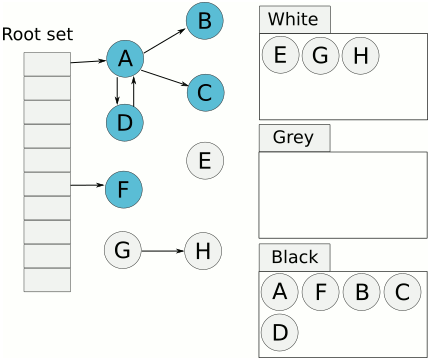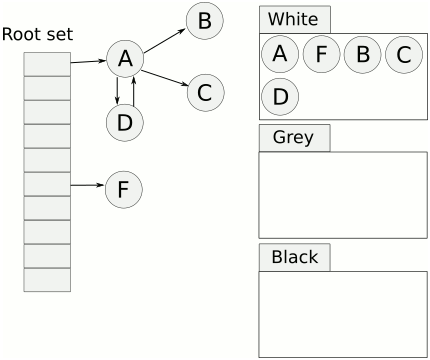
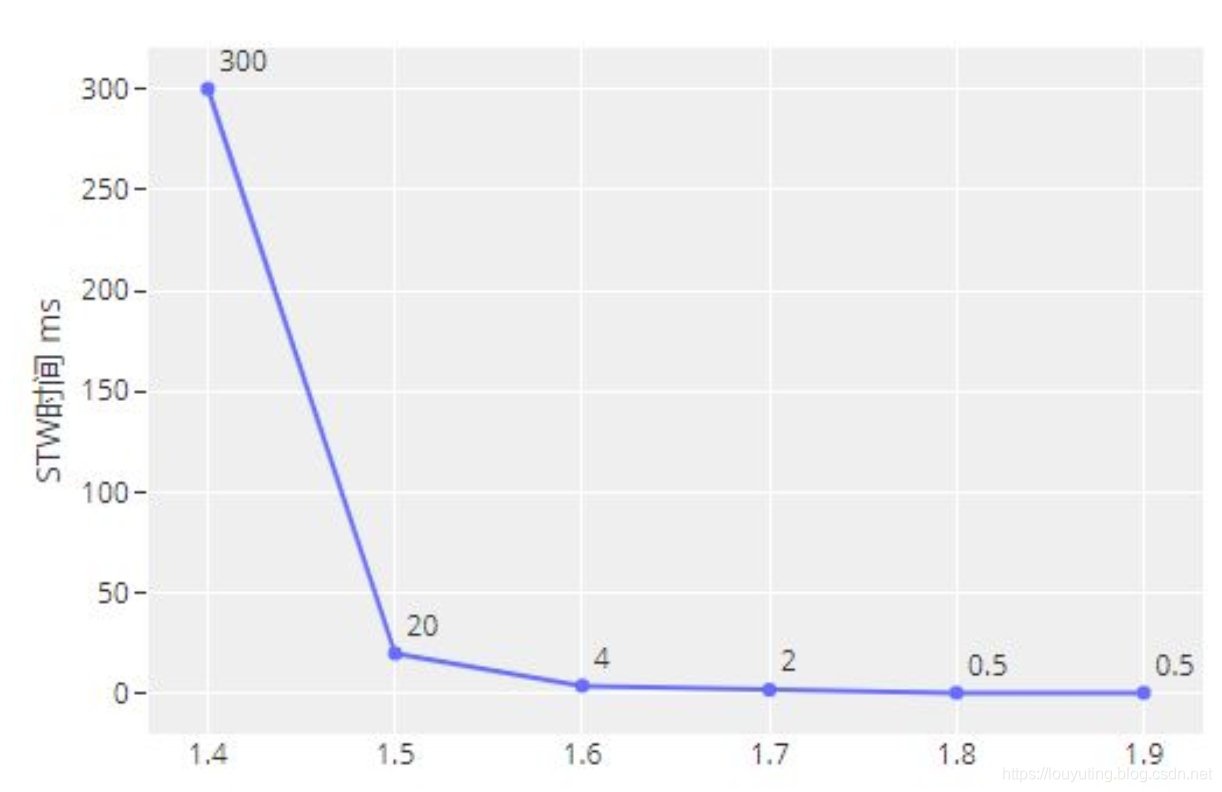
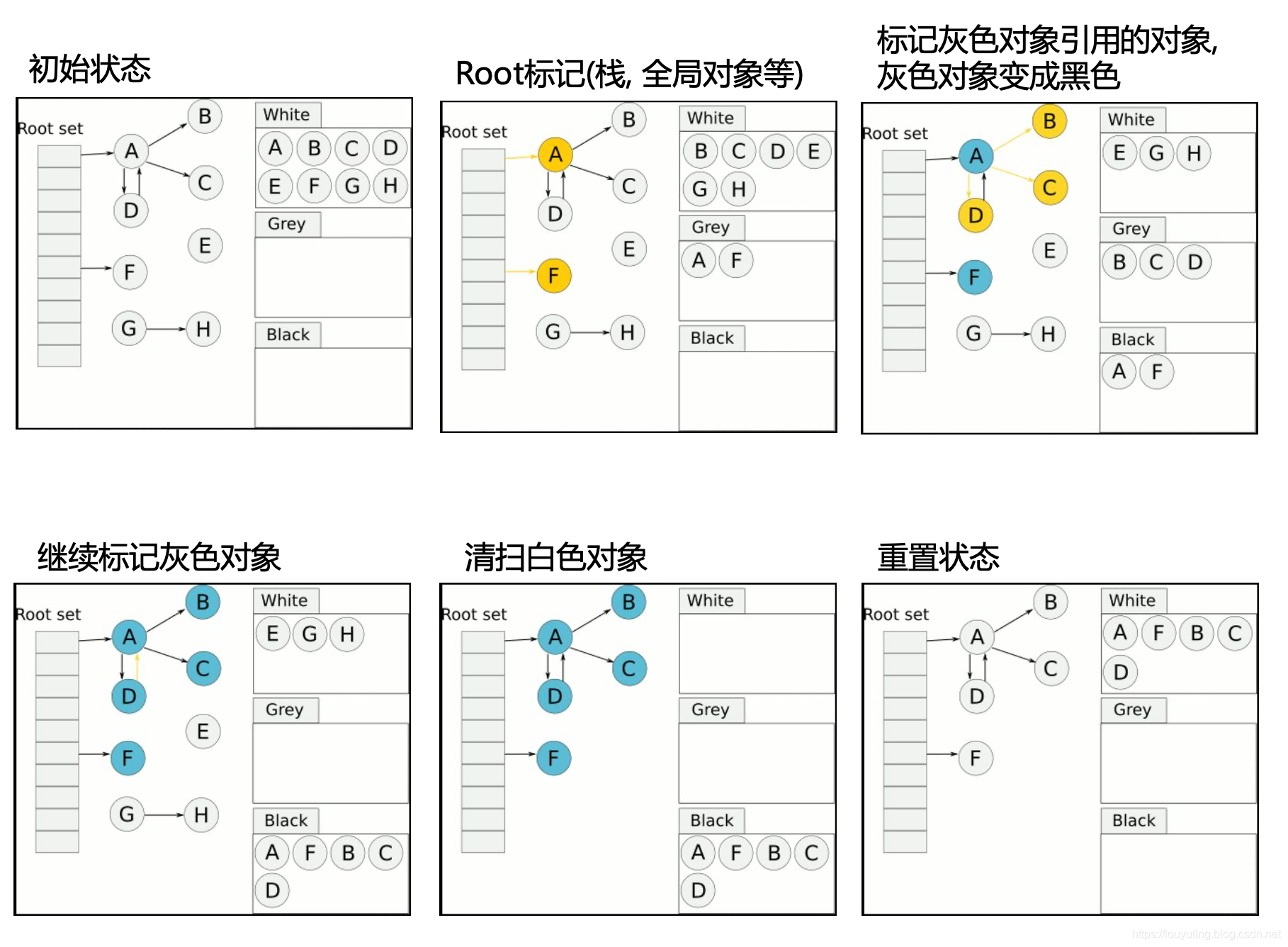
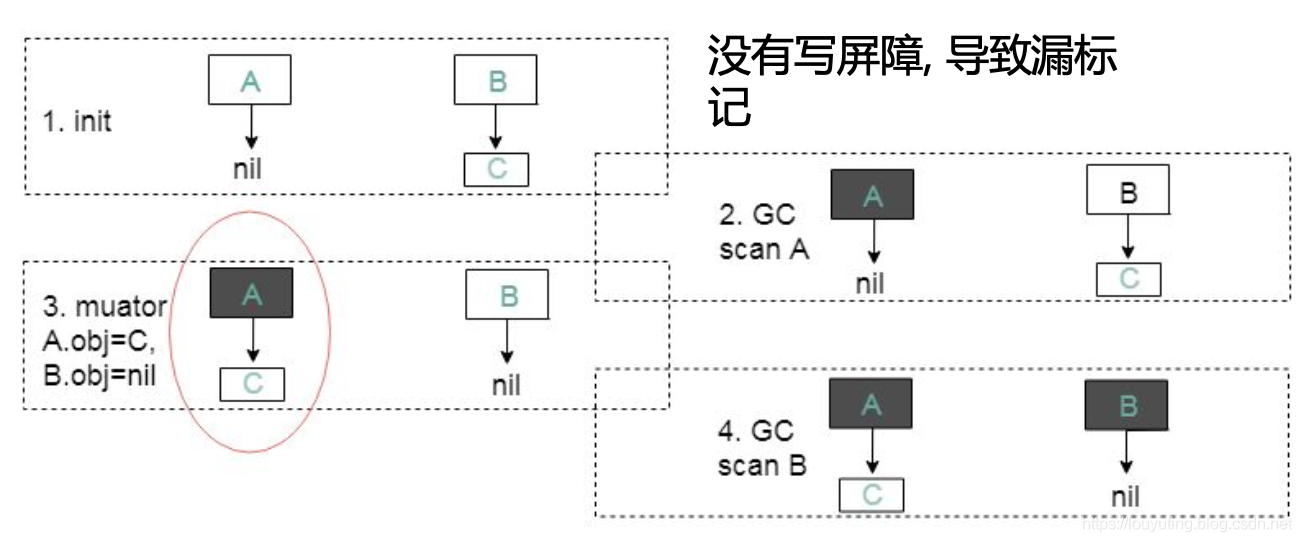
基于追踪的垃圾回收算法(标记清除、复制算法)一个主要问题是在生命周期较长的对象上浪费时间(长生命周期的对象是不需要频繁扫描的)。同时,内存分配存在这么一个事实 “most object die young”。基于这两点,分代垃圾回收算法将对象按生命周期长短存放到堆上的两个(或者更多)区域,这些区域就是分代(generation)。对于新生代的区域的垃圾回收频率要明显高于老年代区域。
const( // gcTriggerHeap indicates that a cycle should be started when // the heap size reaches the trigger heap size computed by the // controller. gcTriggerHeap gcTriggerKind = iota // gcTriggerTime indicates that a cycle should be started when // it's been more than forcegcperiod nanoseconds since the // previous GC cycle. gcTriggerTime // gcTriggerCycle indicates that a cycle should be started if // we have not yet started cycle number gcTrigger.n (relative // to work.cycles). gcTriggerCycle ) // A gcTrigger is a predicate for starting a GC cycle. Specifically, // it is an exit condition for the _GCoff phase. type gcTrigger struct { kind gcTriggerKind now int64 // gcTriggerTime: current time n uint32 // gcTriggerCycle: cycle number to start }
// test reports whether the trigger condition is satisfied, meaning // that the exit condition for the _GCoff phase has been met. The exit // condition should be tested when allocating. func (t gcTrigger) test() bool { if !memstats.enablegc || panicking != 0 || gcphase != _GCoff { returnfalse } switch t.kind { case gcTriggerHeap: // Non-atomic access to heap_live for performance. If // we are going to trigger on this, this thread just // atomically wrote heap_live anyway and we'll see our // own write. return memstats.heap_live >= memstats.gc_trigger case gcTriggerTime: if gcpercent < 0 { returnfalse } lastgc := int64(atomic.Load64(&memstats.last_gc_nanotime)) return lastgc != 0 && t.now-lastgc > forcegcperiod case gcTriggerCycle: // t.n > work.cycles, but accounting for wraparound. return int32(t.n-work.cycles) > 0 } returntrue }
// runtime/mgcwork.go type struct p { ....... // gcw is this P's GC work buffer cache. The work buffer is // filled by write barriers, drained by mutator assists, and // disposed on certain GC state transitions. gcw gcWork ...... }
type gcWork struct { // wbuf1 and wbuf2 are the primary and secondary work buffers. wbuf1, wbuf2 *workbuf
// Bytes marked (blackened) on this gcWork. This is aggregated // into work.bytesMarked by dispose. bytesMarked uint64
// Scan work performed on this gcWork. This is aggregated into // gcController by dispose and may also be flushed by callers. scanWork int64 ...... }
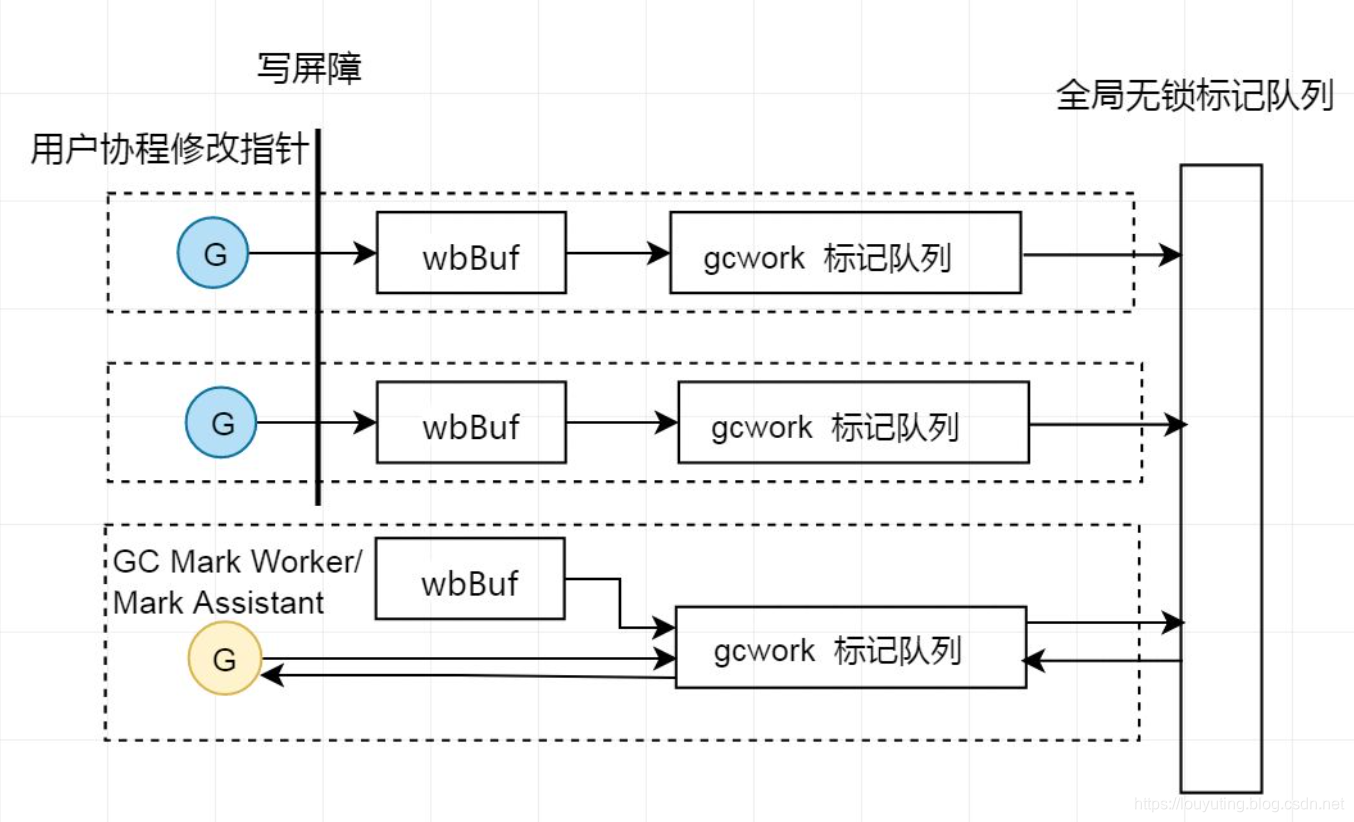
Per P 的 gcWork 是一个典型的生产者和消费者模型,gcWork队列里面保存的就是灰色对象。Write barriers, root discovery, stack scanning, and object scanning 都是生产者,辅助GC是消费者。
//runtime/mgc.go var work struct { full lfstack // lock-free list of full blocks workbuf empty lfstack // lock-free list of empty blocks workbuf pad0 cpu.CacheLinePad // prevents false-sharing between full/empty and nproc/nwait
wbufSpans struct { lock mutex // free is a list of spans dedicated to workbufs, but // that don't currently contain any workbufs. free mSpanList // busy is a list of all spans containing workbufs on // one of the workbuf lists. busy mSpanList } ...... bytesMarked uint64 ...... }
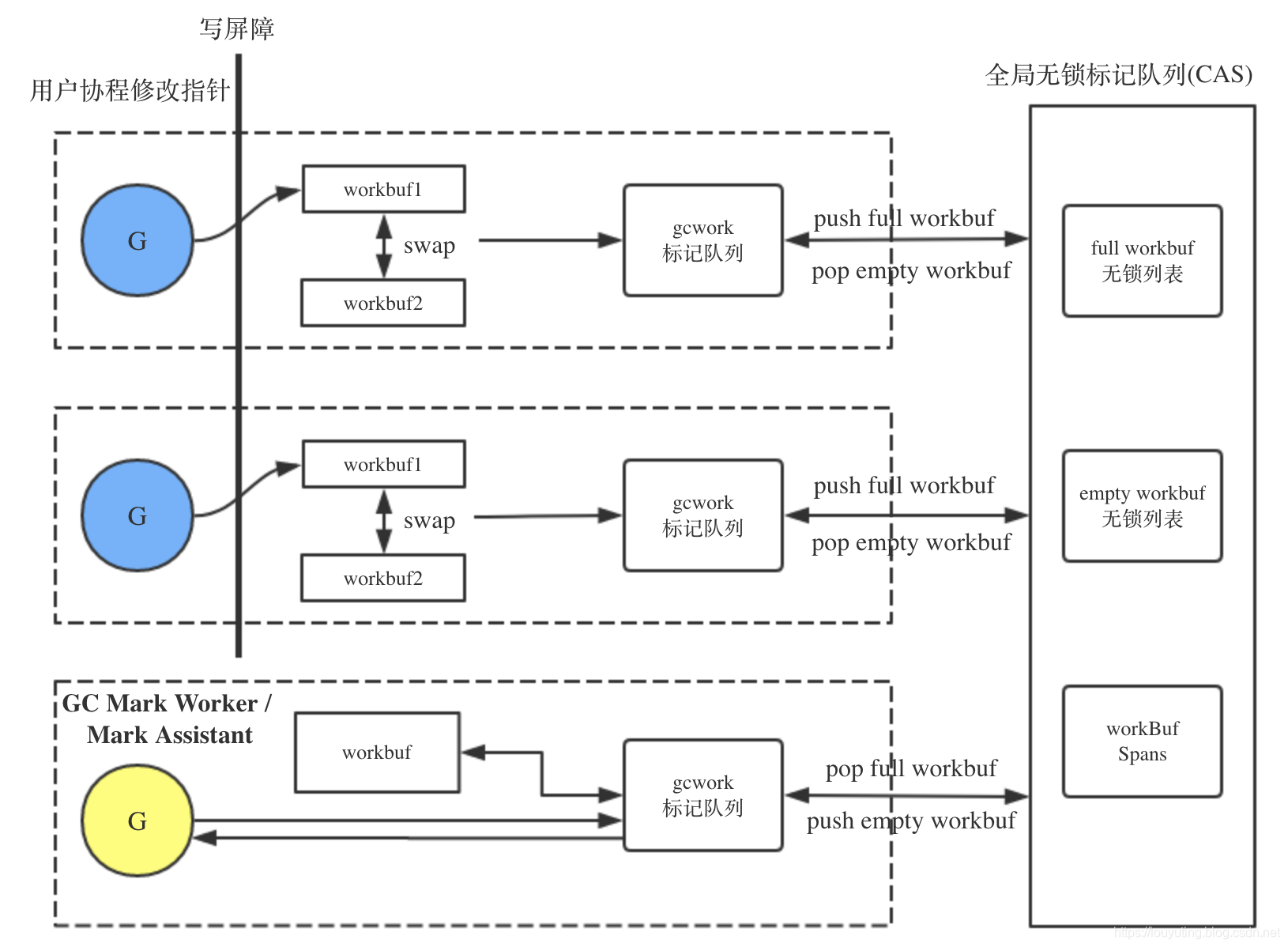
整体high level 结构概括如下图: 这里gcWork为什么使用两个work buffer (wbuf1 和 wbuf2)呢? 比如我现在要 get 一个 灰色对象出来,先从 wbuf1 中取,wbuf1 为空的话则wbuf1与wbuf2 swap 再 get。在其他时间将 work buffer 中的 full 或者 empty buffer 迁移到 global 的 work 中。这样的好处在于将 get 或 put 操作的成本分摊到至少一个 work buffer 上,并减少全局work list上的争用。这里有趣的是 global 的 work full 和 empty list 是 lock-free 的,通过原子操作 cas 等实现。
getempty 函数会从全局的 work.empty list 中 pop一个 empty work buffer; trygetfull 函数会从全局work队列中pop一个full work buffer, 如果不存在full work buffer,则会pop一个局部为空的work buffer。
我们可以看到gcWork初始化的时候:
wbuf1会获取一个空的work buffer;
wbuf2 会尽可能获取一个full work buffer,如果获取不到就会获取局部为空或者全部为空的work buffer;
// If we put a buffer on full, let the GC controller know so // it can encourage more workers to run. We delay this until // the end of put so that w is in a consistent state, since // enlistWorker may itself manipulate w. if flushed && gcphase == _GCmark { gcController.enlistWorker() } }
func gcBgMarkStartWorkers() { // Background marking is performed by per-P G's. Ensure that // each P has a background GC G. for _, p := range allp { if p.gcBgMarkWorker == 0 { go gcBgMarkWorker(p) // 启动后等待该任务通知信号量bgMarkReady再继续 notetsleepg(&work.bgMarkReady, -1) noteclear(&work.bgMarkReady) } } }
// gcDrain scans roots and objects in work buffers, blackening grey // objects until it is unable to get more work. It may return before // GC is done; it's the caller's responsibility to balance work from // other Ps. func gcDrain(gcw *gcWork, flags gcDrainFlags) { ...... // 如果根对象未扫描完, 则先扫描根对象 if work.markrootNext < work.markrootJobs { for !(preemptible && gp.preempt) { // 从根对象扫描队列取出一个值(原子递增) job := atomic.Xadd(&work.markrootNext, +1) - 1 if job >= work.markrootJobs { break } // 执行根对象扫描工作 markroot(gcw, job) if check != nil && check() { goto done } } }
// 根对象已经在标记队列中, 消费标记队列 // 如果标记了preemptible, 循环直到被抢占 // Drain heap marking jobs. for !(preemptible && gp.preempt) { // 如果全局标记队列为空, 把本地标记队列的一部分工作分过去 // (如果wbuf2不为空则移动wbuf2过去, 否则移动wbuf1的一半过去) if work.full == 0 { gcw.balance() } // 从本地标记队列中获取对象, 获取不到则从全局标记队列获取 b := gcw.tryGetFast() if b == 0 { b = gcw.tryGet() if b == 0 { // Flush the write barrier // buffer; this may create // more work. wbBufFlush(nil, 0) b = gcw.tryGet() } } // 获取不到对象, 标记队列已为空, 跳出循环 if b == 0 { // Unable to get work. break } // 扫描获取到的对象 scanobject(b, gcw)
func gcMarkDone() { ...... //记录完成标记阶段开始的时间和STW开始的时间 // There was no global work, no local work, and no Ps // communicated work since we took markDoneSema. Therefore // there are no grey objects and no more objects can be // shaded. Transition to mark termination. now := nanotime() work.tMarkTerm = now work.pauseStart = now getg().m.preemptoff = "gcing" if trace.enabled { traceGCSTWStart(0) } // !!!!!!!!!!!!!!!! // 世界已停止(STW)... // !!!!!!!!!!!!!!!! // STW systemstack(stopTheWorldWithSema) // 禁止辅助GC和后台标记任务的运行 atomic.Store(&gcBlackenEnabled, 0)
func gcMarkTermination(nextTriggerRatio float64) { // World is stopped. // Start marktermination which includes enabling the write barrier. // 禁止辅助GC和后台标记任务的运行 atomic.Store(&gcBlackenEnabled, 0) setGCPhase(_GCmarktermination)
...... systemstack(func() { // 开始STW中的标记 gcMark(startTime) // Must return immediately. // The outer function's stack may have moved // during gcMark (it shrinks stacks, including the // outer function's stack), so we must not refer // to any of its variables. Return back to the // non-system stack to pick up the new addresses // before continuing. })
// Free stack spans. This must be done between GC cycles. systemstack(freeStackSpans)
// Ensure all mcaches are flushed. Each P will flush its own // mcache before allocating, but idle Ps may not. Since this // is necessary to sweep all spans, we need to ensure all // mcaches are flushed before we start the next GC cycle. systemstack(func() { forEachP(func(_p_ *p) { _p_.mcache.prepareForSweep() }) }) ...... }
func gcSweep(mode gcMode) { if gcphase != _GCoff { throw("gcSweep being done but phase is not GCoff") }
lock(&mheap_.lock) // 增加sweepgen, 这样sweepSpans中两个队列角色会交换, 所有span都会变为"待清扫"的span mheap_.sweepgen += 2 mheap_.sweepdone = 0 if mheap_.sweepSpans[mheap_.sweepgen/2%2].index != 0 { // We should have drained this list during the last // sweep phase. We certainly need to start this phase // with an empty swept list. throw("non-empty swept list") } mheap_.pagesSwept = 0 mheap_.sweepArenas = mheap_.allArenas mheap_.reclaimIndex = 0 mheap_.reclaimCredit = 0 unlock(&mheap_.lock)
if !_ConcurrentSweep || mode == gcForceBlockMode { ...... return }
func gcenable() { // Kick off sweeping and scavenging. c := make(chan int, 2) go bgsweep(c) go bgscavenge(c) <-c <-c memstats.enablegc = true// now that runtime is initialized, GC is okay }
func bgsweep(c chan int) { sweep.g = getg() // 等待唤醒 lock(&sweep.lock) sweep.parked = true c <- 1 goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1) // 循环清扫 for { // 清扫一个span, 然后进入调度(一次只做少量工作) forsweepone() != ^uintptr(0) { sweep.nbgsweep++ Gosched() } // 释放一些未使用的标记队列缓冲区到heap forfreeSomeWbufs(true) { Gosched() } lock(&sweep.lock) // 如果清扫未完成则继续循环 if !isSweepDone() { // This can happen if a GC runs between // gosweepone returning ^0 above // and the lock being acquired. unlock(&sweep.lock) continue } sweep.parked = true // 否则让后台清扫任务进入休眠, 当前M继续调度 goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1) } }
// sweepone sweeps some unswept heap span and returns the number of pages returned // to the heap, or ^uintptr(0) if there was nothing to sweep. func sweepone() uintptr { ...... // Find a span to sweep. var s *mspan sg := mheap_.sweepgen for { // 从sweepSpans中取出一个span s = mheap_.sweepSpans[1-sg/2%2].pop() // 全部清扫完毕时跳出循环 if s == nil { atomic.Store(&mheap_.sweepdone, 1) break } // 其他M已经在清扫这个span时跳过 if state := s.state.get(); state != mSpanInUse { // This can happen if direct sweeping already // swept this span, but in that case the sweep // generation should always be up-to-date. if !(s.sweepgen == sg || s.sweepgen == sg+3) { print("runtime: bad span s.state=", state, " s.sweepgen=", s.sweepgen, " sweepgen=", sg, "\n") throw("non in-use span in unswept list") } continue } // 原子增加span的sweepgen, 失败表示其他M已经开始清扫这个span, 跳过 if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) { break } }
// Sweep the span we found. npages := ^uintptr(0) if s != nil { npages = s.npages if s.sweep(false) { // Whole span was freed. Count it toward the // page reclaimer credit since these pages can // now be used for span allocation. atomic.Xadduintptr(&mheap_.reclaimCredit, npages) } else { // Span is still in-use, so this returned no // pages to the heap and the span needs to // move to the swept in-use list. npages = 0 } } // 更新同时执行sweep的任务数量 // Decrement the number of active sweepers and if this is the // last one print trace information. if atomic.Xadd(&mheap_.sweepers, -1) == 0 && atomic.Load(&mheap_.sweepdone) != 0 { ...... } _g_.m.locks-- return npages }
func (s *mspan) sweep(preserve bool) bool { // It's critical that we enter this function with preemption disabled, // GC must not start while we are in the middle of this function. _g_ := getg() if _g_.m.locks == 0 && _g_.m.mallocing == 0 && _g_ != _g_.m.g0 { throw("mspan.sweep: m is not locked") } sweepgen := mheap_.sweepgen if state := s.state.get(); state != mSpanInUse || s.sweepgen != sweepgen-1 { print("mspan.sweep: state=", state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("mspan.sweep: bad span state") }
spc := s.spanclass size := s.elemsize res := false
c := _g_.m.mcache freeToHeap := false
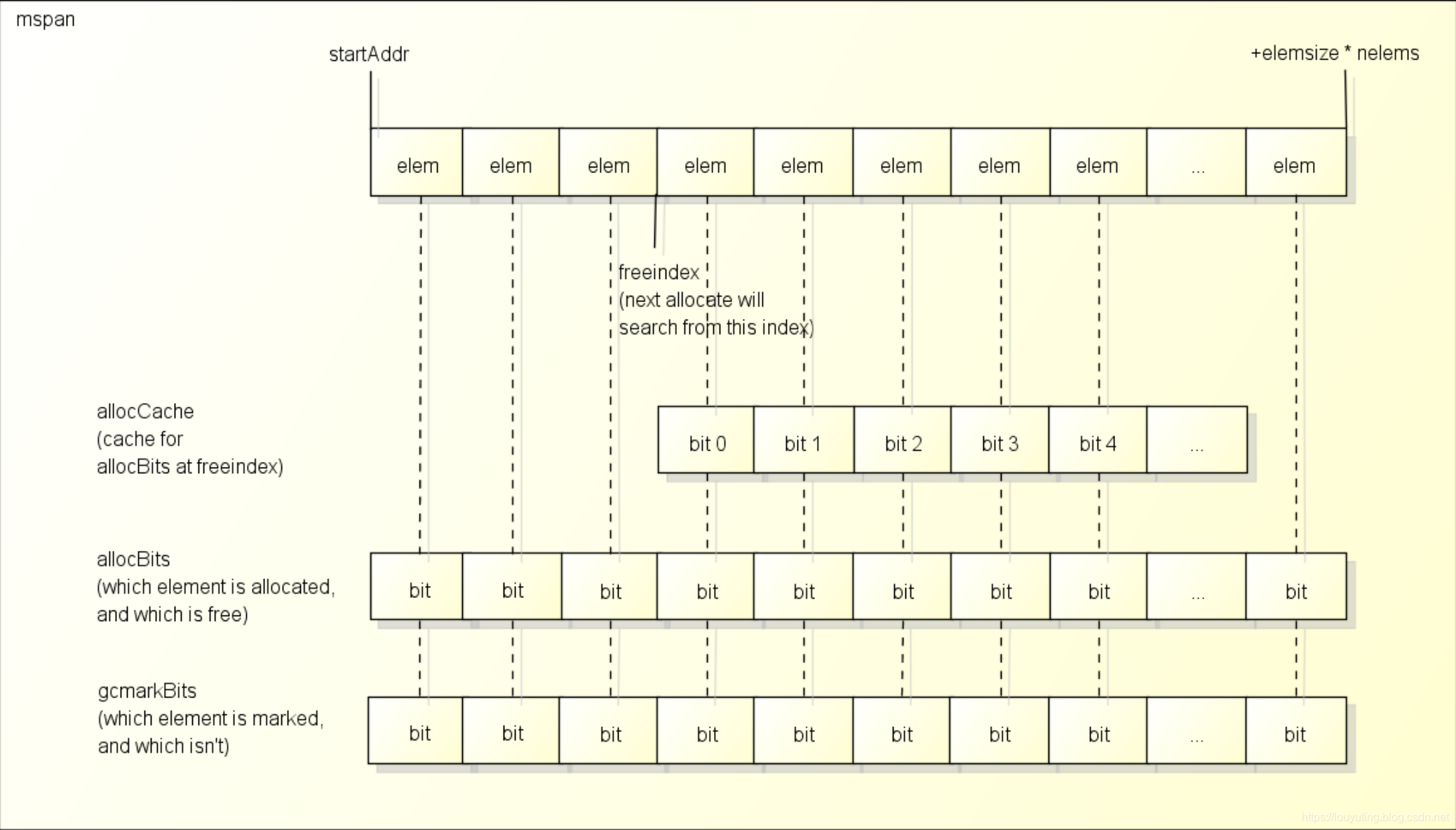
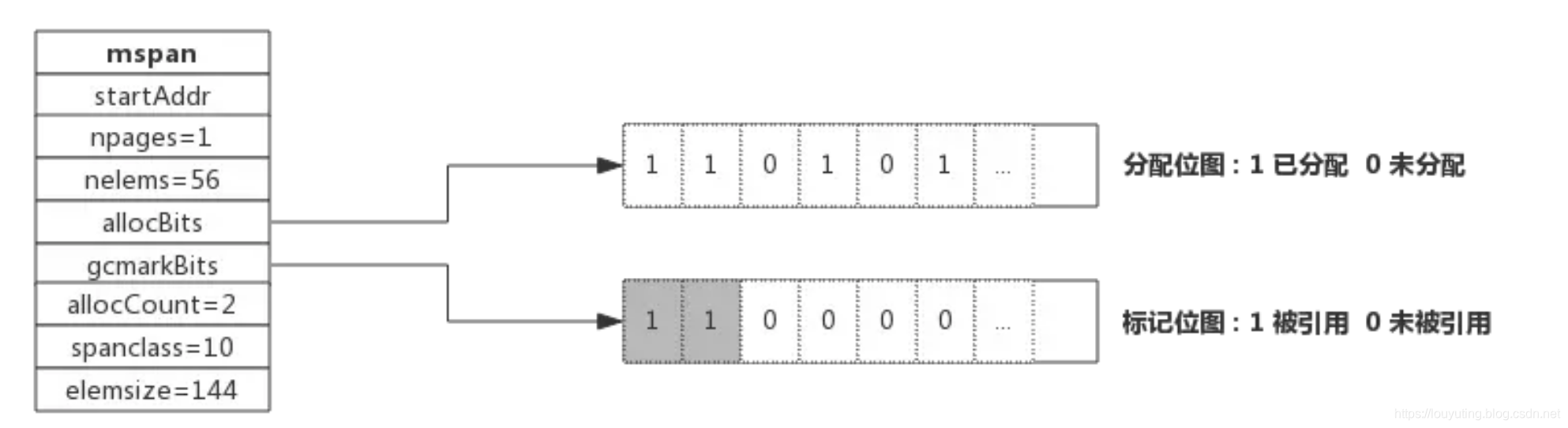
// The allocBits indicate which unmarked objects don't need to be // processed since they were free at the end of the last GC cycle // and were not allocated since then. // If the allocBits index is >= s.freeindex and the bit // is not marked then the object remains unallocated // since the last GC. // This situation is analogous to being on a freelist.
// Unlink & free special records for any objects we're about to free. // Two complications here: // 1. An object can have both finalizer and profile special records. // In such case we need to queue finalizer for execution, // mark the object as live and preserve the profile special. // 2. A tiny object can have several finalizers setup for different offsets. // If such object is not marked, we need to queue all finalizers at once. // Both 1 and 2 are possible at the same time. specialp := &s.specials special := *specialp for special != nil { // A finalizer can be set for an inner byte of an object, find object beginning. objIndex := uintptr(special.offset) / size p := s.base() + objIndex*size mbits := s.markBitsForIndex(objIndex) if !mbits.isMarked() { // This object is not marked and has at least one special record. // Pass 1: see if it has at least one finalizer. hasFin := false endOffset := p - s.base() + size for tmp := special; tmp != nil && uintptr(tmp.offset) < endOffset; tmp = tmp.next { if tmp.kind == _KindSpecialFinalizer { // Stop freeing of object if it has a finalizer. mbits.setMarkedNonAtomic() hasFin = true break } } // Pass 2: queue all finalizers _or_ handle profile record. for special != nil && uintptr(special.offset) < endOffset { // Find the exact byte for which the special was setup // (as opposed to object beginning). p := s.base() + uintptr(special.offset) if special.kind == _KindSpecialFinalizer || !hasFin { // Splice out special record. y := special special= special.next *specialp = special freespecial(y, unsafe.Pointer(p), size) } else { // This is profile record, but the object has finalizers (so kept alive). // Keep special record. specialp = &special.next special= *specialp } } } else { // object is still live: keep special record specialp = &special.next special= *specialp } }
......
// Count the number of free objects in this span. nalloc := uint16(s.countAlloc()) if spc.sizeclass() == 0 && nalloc == 0 { s.needzero = 1 freeToHeap = true } nfreed := s.allocCount - nalloc if nalloc > s.allocCount { print("runtime: nelems=", s.nelems, " nalloc=", nalloc, " previous allocCount=", s.allocCount, " nfreed=", nfreed, "\n") throw("sweep increased allocation count") }
s.allocCount = nalloc wasempty := s.nextFreeIndex() == s.nelems s.freeindex = 0// reset allocation index to start of span. if trace.enabled { getg().m.p.ptr().traceReclaimed += uintptr(nfreed) * s.elemsize }
// gcmarkBits becomes the allocBits. // get a fresh cleared gcmarkBits in preparation for next GC s.allocBits = s.gcmarkBits s.gcmarkBits = newMarkBits(s.nelems)
// We need to set s.sweepgen = h.sweepgen only when all blocks are swept, // because of the potential for a concurrent free/SetFinalizer. // But we need to set it before we make the span available for allocation // (return it to heap or mcentral), because allocation code assumes that a // span is already swept if available for allocation. if freeToHeap || nfreed == 0 { // The span must be in our exclusive ownership until we update sweepgen, // check for potential races. if state := s.state.get(); state != mSpanInUse || s.sweepgen != sweepgen-1 { print("mspan.sweep: state=", state, " sweepgen=", s.sweepgen, " mheap.sweepgen=", sweepgen, "\n") throw("mspan.sweep: bad span state after sweep") } // Serialization point. // At this point the mark bits are cleared and allocation ready // to go so release the span. atomic.Store(&s.sweepgen, sweepgen) }
if nfreed > 0 && spc.sizeclass() != 0 { c.local_nsmallfree[spc.sizeclass()] += uintptr(nfreed) res = mheap_.central[spc].mcentral.freeSpan(s, preserve, wasempty) // mcentral.freeSpan updates sweepgen } elseif freeToHeap { // Free large span to heap
// NOTE(rsc,dvyukov): The original implementation of efence // in CL 22060046 used sysFree instead of sysFault, so that // the operating system would eventually give the memory // back to us again, so that an efence program could run // longer without running out of memory. Unfortunately, // calling sysFree here without any kind of adjustment of the // heap data structures means that when the memory does // come back to us, we have the wrong metadata for it, either in // the mspan structures or in the garbage collection bitmap. // Using sysFault here means that the program will run out of // memory fairly quickly in efence mode, but at least it won't // have mysterious crashes due to confused memory reuse. // It should be possible to switch back to sysFree if we also // implement and then call some kind of mheap.deleteSpan. if debug.efence > 0 { s.limit = 0// prevent mlookup from finding this span sysFault(unsafe.Pointer(s.base()), size) } else { mheap_.freeSpan(s, true) } c.local_nlargefree++ c.local_largefree += size res=true } if !res { // The span has been swept and is still in-use, so put // it on the swept in-use list. mheap_.sweepSpans[sweepgen/2%2].push(s) } return res }